The rise in usage of cloud computing resources and container management platforms for executing AI (Artificial Intelligence) and ML (Machine Learning) workloads has led many engineers and companies to question the suitability and effectiveness of Kubernetes' resource management and scheduling to meet the growing requirements of these workloads.
So why's that? What patterns, architectures, and procedures has led these companies and engineers to this problem of scaling ML platforms on Kubernetes? And what kind of solution could we apply to help solve those problems?
To begin with, some of the typical machine learning and deep learning frameworks, such as Spark, Flink, Kubeflow, FfDL, Meltano etc., require multiple learners or executors to be concurrently scheduled and started in order for the application to be able to run.
Furthermore, co-locating these workers on the same node, or placing them on topologically close nodes, say by zone or region, is supposed to minimize the communication delays of large data sets. More recent trends show tendency towards massively parallel and elastic jobs, where a large number of short running tasks (minutes, seconds, or even less) is spawned to consume the available resources.
The more resources that can be dedicated to start more parallel tasks, the faster the job will finish! In the end, the amount of consumed resources is going to be more or less the same, but it is the overall job response time that is going to be slowed if the allocated resources are constrained.
New use cases have also emerged where developers use these frameworks to gain insights by performing interactive exploration of data. For example a data scientist using a Jupyter notebook may issue commands to start a ML job to analyze a big data set waiting for the results to start a subsequent processing job, in an interactive session.
Managing Jobs and Tasks
When dealing with millions of AI/ML jobs submitted on daily or even hourly basis, high variability in the demand for resources is created.
Some of these jobs may arrive almost simultaneously, creating a backlog of work, and require an arbitration policy that decides which job goes first given the current cloud resources available.
These priorities, service classes, user quotas, and more constraints enable the formulation of meaningful policies, from users' perspectives, and linking those policies to a charging model.
For scarce resources, such as GPUs and TPUs, the ability to buffer and prioritize jobs, as well as enforcing quotas, becomes crucial. Note that whole jobs, as opposed to individual tasks, is the subject of queuing and control, since it does not make much sense to focus only on individual tasks, as the partial execution of tasks from multiple jobs may lead to partial deadlocks, and many jobs may be simultaneously active while none is able to proceed to completion.
Stuck on Cloud 9
Cloud computing companies are real companies too.
The reality that cloud computing operators face is having to operate profitable businesses that offer reasonable pricing of offered resources and services.
These prices cannot be reasonable if the cloud provider has to own seemingly infinite resources. In fact, minimizing their cost starts with operating their physical resources (hardware) at higher utilization points. Luckily, the common wisdom phrase did not state that the cloud is the limit but rather that the sky is.
At the cluster level, cluster owners may request to expand or shrink their cluster resources, and all providers offer the ability to do that. However, response times vary; typically, it is on the order of minutes, and depends on how many additional worker nodes are being added.
In the case of bare-metal machines with special hardware configuration, like certain GPU type for example, it may take longer to fulfill a cluster scale up request, and come with an increased chance of failure.
While cluster scaling is a useful mechanism for longer capacity planning, cluster owners cannot rely on this mechanism to respond to instantaneous demand fluctuations induced by resource hungry AI and ML workloads.
More Clouds, More Clusters, More Problems
The typical enterprise today is using services from multiple cloud providers. An organization owning and operating many Kubernetes clusters is not uncommon today.
Smaller clusters are easier to manage, and in the case of failure, the blast radius of impacted applications and users is limited. This is why a sharded, multi-cluster architecture appeals to both service providers and operations teams.
This architecture creates an additional management decision that needs to be made when running a certain AI workload regarding where to run it; what cluster should this workload run on? A static assignment of users or application sets to clusters is too naive to efficiently utilize available multi-cluster resources.
Hybrid Cloud and Edge Computing
A scenario, which is often cited as an advantage of cloud computing, is the ability to pour over from private infrastructure into public cloud at times of unexpected or seasonal high demands.
While with traditional retail applications this seasonality may be well anticipated, on the other hand, with AI and ML workloads in general this need for offloading local resources or pouring into a public cloud may arise more frequently and at any time.
With resource hungry, large parallel jobs that could start at any moment, the need to instantaneously pour over from private to public cloud in a dynamically managed seamless way has become a real need of large enterprises, big data companies, and even for some startups.
Advancements in the field of IoT (Internet of Things) and the surge in use of devices and sensors at the edge of the network, has led to the emergence of Edge Computing as a new paradigm.
In this paradigm, the compute power is brought closer to data sources, where initial data analysis and learning steps may take place near the data generation sources, instead of the overhead of having to transfer enormous data streams all the way back to a centralized cloud computing location.
In some situations, this data streaming may not be feasible due to lack of availability of fast and reliable network connectivity, and hence the need for Kubernetes clusters at the edge of the network.
Can The Kubernetes Scheduler Handle Everything?
Now that we have covered the landscape of issues, as well as evolving runtime patterns, associated with executing AI workloads in the cloud, we can look at what the Kubernetes scheduler is good at addressing and what it is not suited for.
The scheduler is responsible for the placement of pods (the atomic unit of Kubernetes; you can think of it as a container on a machine) within a Kubernetes cluster. It is part and parcel of the Kubernetes architecture and it is good for placing pods on the right worker nodes, within a cluster, while maintaining constraints such as available capacity, resource requests and limits, and certain nodes.
A pod may represent a task in a job, a job itself, or an executor in which multiple tasks may be executed by the AI/ML framework. Discussing these different execution models for frameworks and the pros and cons of each is way beyond the scope of this article.
What the Kubernetes scheduler cannot do is managing jobs holistically. It is quite obvious in the multi-cluster and hybrid scenarios that a scheduler sitting within a single cluster cannot have the global view to dispatch jobs to multiple clusters.
Even in single cluster environments, it lacks the ability to manage jobs, and instead jobs have to be broken down, immediately as soon as they are received by the Kubernetes API server, to their constituting pods and submitted to the scheduler.
This may cause a problem of excessive numbers of pending pods, in times of high demand, which may overwhelm the scheduler other controllers, and the underlying etcd persistence layer, which slows down the overall cluster performance significantly.
A Solution
All the above indicates that something is missing in the overall approach to resource management of AI/ML workloads in Kubernetes based environments, and suggests that the best way to manage such workloads is to follow a two-level resource management approach that is "Kube-native".
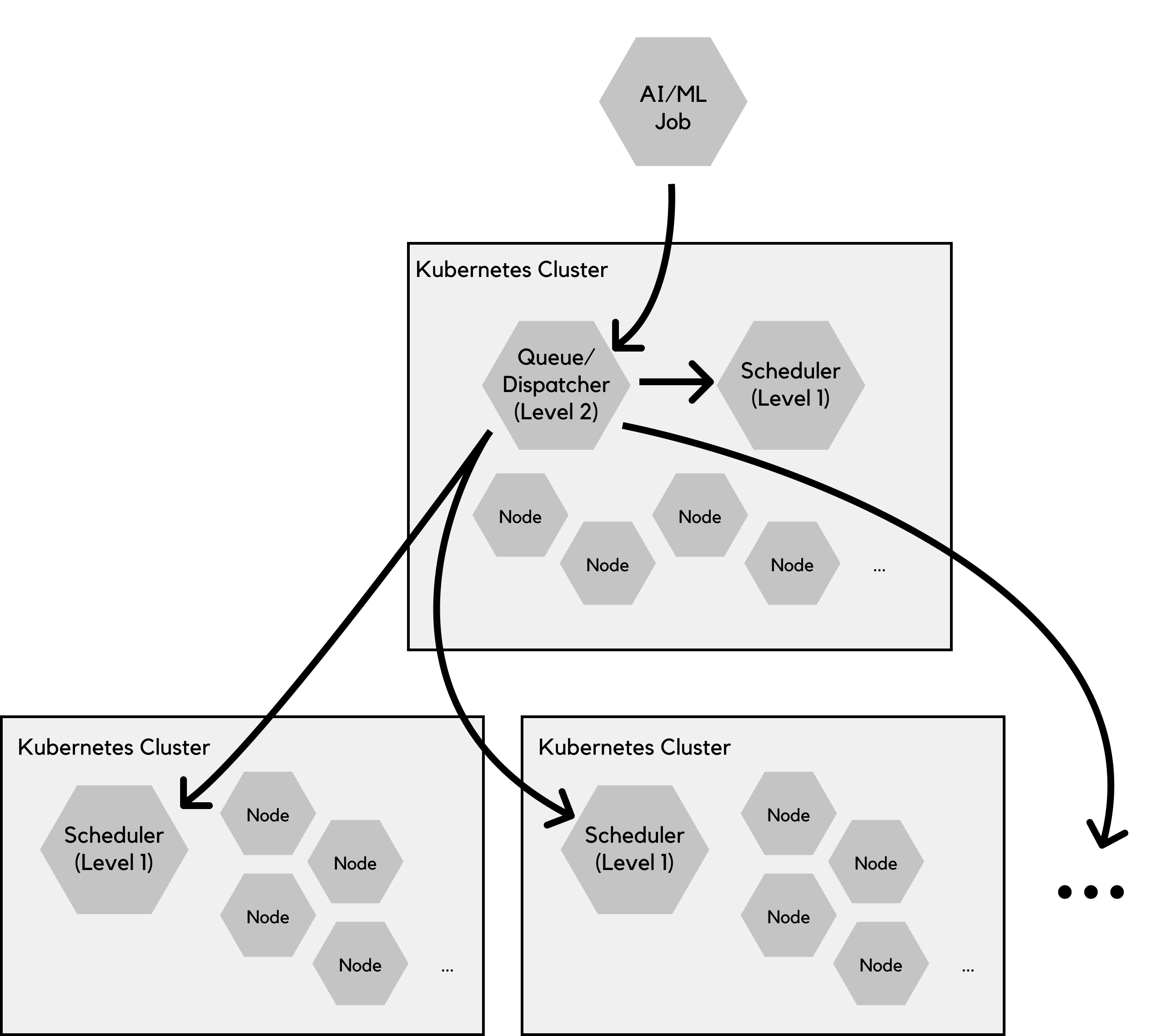
So what's kube-native?
Something is kube-native if it is built as a Kubernetes extension using the extensible frameworks that it offers. Any new resource management component should be realized as a Kubernetes operator. In addition, the API that manages the AI/ML workflows and mechanisms, which is exposed to end users and admins, should be a seamless extension of the Kubernetes API. Users and admins should be able to use the standard kubectl cli, for example, to manage the AI/ML workflow life-cycle.
Second, what are the two levels of resource management?
The first level is the existing scheduler level.
As explained above, a scheduler responsible for the placement of pods within each Kubernetes cluster is needed for placing pods, or sometimes groups of pods together, on the right nodes, while maintaining constraints such as co-location, co-scheduling, etc.
Your vanilla scheduler does not do all of that, but you can replace it by a scheduler that does all or some of these functions. Several open source schedulers are available, like Volcano, YuniKorn, and Safe Scheduler. Each of these schedulers addresses some of these requirements.
The second level, or the higher level resource manager, is responsible for queuing and dispatching of the AI/ML jobs, and enforcement of user quotas.
Every job submitted to the system is received and queued for execution by the second level resource manager.
It has the responsibility to decide when to release the job to be served, and where that job should be served, i.e., on which cluster. It implements policies that regulate the flow of jobs to the clusters, allocate resources to jobs at coarse granularity level, and realize the SLA differentiation imposed by priorities or classes of service.
The important thing to note about the resource manager is that it operates on the job level, not the task or pod level, hence the lower lever (first level) schedulers, running in each cluster, are not overwhelmed with pending pods that should not be executed yet. Also, once a decision is made to execute a job, its corresponding resources, including its pods, are created only on the selected target cluster, at that moment.
In order to perform its job properly and be able to make these decisions, the second level resource manager needs to tap into the resource monitoring streams on the target clusters.
Coupled with the right policy configurations, this pattern is capable of queuing and dispatching jobs properly. Depending on implementation details, the second level manager may require an agent on each target cluster to assist it in accomplishing its goals. The agent would receive the dispatched job and locally create its corresponding pods, in this case, instead of the dispatcher creating them remotely.